平台设计与实现¶
本章首先介绍深度强化学习的核心问题及其形式化建模,随后介绍平台的整体架构、模块设计和实现细节,最后简要提及平台的外围支持。
深度强化学习问题描述¶
强化学习问题不同于机器学习领域中的监督学习问题或无监督学习问题。给定一个输入 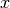 ,这三种学习类型的算法会有不同的输出:
,这三种学习类型的算法会有不同的输出:
监督学习:输出预测值
 ;
;无监督学习:输出
的潜在模式  ,如聚类、密度估计、降维、隐变量推理等;
,如聚类、密度估计、降维、隐变量推理等;强化学习:输出动作
 使得能够最大化期望累计奖励。
使得能够最大化期望累计奖励。
强化学习算法是在不确定环境中,通过与环境的不断交互,来不断优化自身策略的算法。它和监督学习、非监督学习有着一些本质上的区别:
获取的数据非独立同分布:大部分机器学习算法假设数据是独立同分布的,否则会有收敛性问题;然而智能体与环境进行交互产生的数据具有很强的时间相关性,无法在数据层面做到完全的解耦,不满足数据的独立同分布性质,因此强化学习算法训练并不稳定;智能体的行为同时会影响后续的数据分布;
没有“正确”的行为,且无法立刻获得反馈:监督学习有专门的样本标签,而强化学习并没有类似的强监督信号,通常只有基于奖励函数的单一信号;强化学习场景存在延迟奖励的问题,智能体不能在单个样本中立即获得反馈,需要不断试错,还需要平衡短期奖励与长期奖励的权重;
具有超人类的上限:传统的机器学习算法依赖人工标注好的数据,从中训练好的模型的性能上限是产生数据的模型(人类)的上限;而强化学习可以从零开始和环境进行不断地交互,可以不受人类先验知识的桎梏,从而能够在一些任务中获得超越人类的表现。
问题定义¶

图 2.1:强化学习算法中智能体与环境循环交互的过程¶
强化学习问题是定义在马尔科夫决策过程(Markov Decision Process,MDP)之上的。一个MDP是形如
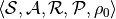 的五元组,其中:
的五元组,其中:
 是所有合法状态的集合;
是所有合法状态的集合; 是所有合法动作的集合;
是所有合法动作的集合;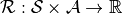 是奖励函数,
是奖励函数,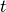 时刻的奖励函数
时刻的奖励函数 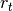 由
由 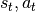 决定,使用
决定,使用 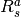 表示在当前状态
表示在当前状态 采取动作之后所能获得的期望奖励;
采取动作之后所能获得的期望奖励; 是状态转移概率函数,使用
是状态转移概率函数,使用 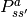 来表示当前状态 采取动作 转移到状态
来表示当前状态 采取动作 转移到状态 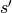 的概率;
的概率; 是初始状态的概率分布,
是初始状态的概率分布,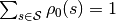 。
。
MDP还具有马尔科夫性质,即在任意 时刻,下一个状态 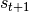 的概率分布只能由当前状态
的概率分布只能由当前状态 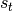 决定,与过去的任何状态
决定,与过去的任何状态 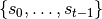 均无关。
均无关。
图 2.1 描述了在经典的强化学习场景中,智能体与环境不断交互的过程:在
时刻,智能体获得了环境状态 ,经过计算输出动作值 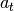 并在环境中执行,环境会返回
并在环境中执行,环境会返回 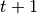 时刻的环境状态
与上一个时刻产生的奖励 。
时刻的环境状态
与上一个时刻产生的奖励 。
在某些场景中,智能体无法获取到整个环境的状态,比如扑克、麻将等不完全信息对弈场景,此时称整个过程为部分可观测马尔科夫决策过程
(Partially Observable Markov Decision
Process,POMDP)。在智能体与环境交互的每个回合中,智能体只能接收到观测值
 ,为状态 的一部分。
,为状态 的一部分。
定义累积折扣回报 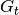 为从 时刻起的加权奖励函数总和
为从 时刻起的加权奖励函数总和

其中 ![\gamma\in [0,1]](../_images/math/cec1a02777451d174a26a4ebd7e63173f29840f6.png) 是折扣因子,衡量了智能体对短期回报与长期回报的权重分配。通常用
是折扣因子,衡量了智能体对短期回报与长期回报的权重分配。通常用
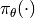 表示一个以参数
表示一个以参数 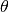 参数化的策略
参数化的策略
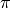 。强化学习算法优化目标是最大化智能体每一回合的累计折扣回报的期望,形式化如下:
。强化学习算法优化目标是最大化智能体每一回合的累计折扣回报的期望,形式化如下:
![\theta^*=\arg\max_\theta \mathbb{E}_{\pi_\theta}[G_t]](../_images/math/7691599f3b83ed8bf08b8b68f65b465a4446b925.png)
智能体的组成¶
一个智能体主要由策略函数(Policy Function)、价值函数(Value Function)和环境模型(Environment Model)三个部分组成。
策略函数: 智能体根据当前环境状态,输出动作值的函数。策略函数分为确定性策略函数与随机性策略函数。
确定性策略函数通常有两种形式:(1)  ,直接输出动作值;(2)
,直接输出动作值;(2) 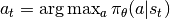 ,评估在状态
下所有可能的策略并从中选取最好的动作。
,评估在状态
下所有可能的策略并从中选取最好的动作。
随机性策略函数的形式主要为计算一个概率分布
 ,从这个概率分布中采样出动作值
。常用的分布有用于离散动作空间的类别分布(Categorical Distribution)、用于连续动作空间的对角高斯分布(Diagonal Gaussian Distribution)。
,从这个概率分布中采样出动作值
。常用的分布有用于离散动作空间的类别分布(Categorical Distribution)、用于连续动作空间的对角高斯分布(Diagonal Gaussian Distribution)。
价值函数: 价值函数是智能体对当前状态、或者是状态-动作对进行评估的函数,主要有三种形式:
状态值函数(State-Value Function)
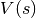 :状态
对应的期望累计折扣回报,
:状态
对应的期望累计折扣回报,![V(s)=\mathbb{E}_\pi[G_t|s_t=s]](../_images/math/f7039f160cc93b372858610728983e9bbf84696b.png) ;
;动作值函数(Action-Value Function)
 :状态
在采取动作
的时候对应的期望累计折扣回报,
:状态
在采取动作
的时候对应的期望累计折扣回报,![Q(s,a)=\mathbb{E}_{\pi}[G_t|s_t=s,a_t=a]](../_images/math/99814d335206816cd30f71c077b1abc90dda2a23.png)
优势函数(Advantage Function)
 :状态
下采取动作
的情况下,比平均情况要好多少,
:状态
下采取动作
的情况下,比平均情况要好多少, 。
。
环境模型: 智能体还可以对环境中的状态转移函数进行建模,比如使用映射
 进行对环境转移
进行对环境转移  的拟合,或者是对奖励函数 的分布进行拟合。
的拟合,或者是对奖励函数 的分布进行拟合。
现有深度强化学习算法分类¶
强化学习算法按照是否对环境进行建模来划分,可分为免模型强化学习(Model-free Reinforcement Learning,MFRL)与基于模型的强化学习(Model-based Reinforcement Learning,MBRL)两大类;此外还有多智能体学习(Multi-agent Reinforcement Learning,MARL)、元强化学习(Meta Reinforcement Learning)、模仿学习(Imitation Learning,IL)这几个大类。现有深度强化学习平台主要实现免模型强化学习算法。
免模型强化学习算法按照模型的学习特性进行区分,可分为同策略学习(On-policy Learning)和异策略学习(Off-policy Learning)。同策略学习指所有与环境交互采样出来的轨迹立即拿去训练策略,训练完毕之后即丢弃;而异策略学习指将所有采集出来的数据存储在一个数据缓冲区中,训练策略时从缓冲区中采样出若干数据组进行训练。
深度强化学习问题的抽象凝练与平台整体设计¶
通过以上描述,现有强化学习算法可以被抽象成如下若干模块:
数据缓冲区(Buffer):无论是同策略学习,还是异策略学习方法,均需要将智能体与环境交互的数据进行封装与存储。例如在DQN [MKS+15] 算法实现中,需要使用重放缓冲区(Replay Buffer)进行相应的数据处理,因此对数据存储的实现是平台底层不可或缺的一部分。
更进一步,可以将同策略学习算法与异策略学习算法的数据存储用数据缓冲区(Buffer)进行统一:异策略学习算法是将缓冲区数据每次采样出一部分,而同策略学习算法可以看做一次性将缓冲区中所有数据采集出来并删除。
策略(Policy):策略是智能体决策的核心部分,将其形式化表示为
(1)¶

其中
 是
时刻策略的隐藏层状态,通常用于循环神经网络(Recurrent Neural
Network,RNN)的训练;
是
时刻策略的隐藏层状态,通常用于循环神经网络(Recurrent Neural
Network,RNN)的训练; 是 时刻策略输出的中间值,以备后续训练时使用。
是 时刻策略输出的中间值,以备后续训练时使用。此外不同策略在训练的时候所需要采样的数据模式不同,比如在计算
 步回报的时候需要从数据缓冲区中采样出连续
帧的数据信息进行计算,因此策略需要有一个专门和数据缓冲区进行交互的接口。
步回报的时候需要从数据缓冲区中采样出连续
帧的数据信息进行计算,因此策略需要有一个专门和数据缓冲区进行交互的接口。策略中还包含模型(Model),包括表格模型、神经网络策略模型、环境模型等。模型可直接与策略进行交互,而不必和其他部分相互耦合。
采集器(Collector):采集器定义了策略与环境(Env)交互的过程。策略在与一个或多个环境交互的过程中会产生一定的数据,由采集器进行收集并存放至数据缓冲区中;在训练策略的时候由采集器从数据缓冲区中采样出数据并进行封装。
在多智能体的情况下,采集器可以承担多个策略之间的交互,并分别存储至不同的数据缓冲区中。
训练器(Trainer):训练器是平台最上层的封装,定义了整个训练过程,与采集器和策略的学习函数进行交互,包含同策略学习与异策略学习两种训练模式。
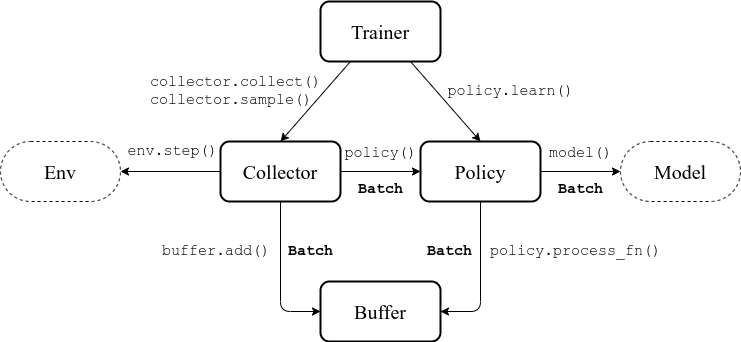
图 2.2:深度强化学习算法模块抽象凝练,暨天授平台总体设计¶
图 2.2 较为直观地描述了上述抽象出的若干模块相互之间的调用关系。其中“Batch”(数据组)为模块之间传递数据信息的封装。平台的整体架构即按照该抽象模式进行设计,其中中间四个模块为平台核心模块。
平台实现¶
数据组(Batch)¶
数据组是平台内部各个模块之间传递数据的数据结构。它支持任意关键字初始化、对任意元素进行修改,以及嵌套调用和格式化输出的功能。如果数据组内各个元素值的第0维大小相等,还可支持切分(split)操作,从而方便地将一组大数据按照固定的大小拆分之后送入策略模块中处理。
平台的内部实现对数据组保留了如下7个关键字:
obs: 时刻的观测值 ;act: 时刻策略采取的动作值 ;rew: 时刻环境反馈的奖励值 ;done: 时刻环境结束标识符
 ,0为未结束,1为结束;
,0为未结束,1为结束;obs_next: 时刻的观测值 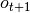 ;
;info: 时刻环境给出的环境额外信息
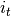 ,以字典形式存储;
,以字典形式存储;policy: 时刻策略在计算过程中产生的数据
,可参考 (1)。
数据缓冲区(Buffer)¶
数据缓冲区存储了策略与环境交互产生的一系列数据,并且支持从已存储数据中采样出固定大小的数据组进行策略学习。底层数据结构主要采用NumPy数组进行存储,能够加快存储效率。
同数据组一样,数据缓冲区同样保留了其中7个保留关键字,其中关键字 info
不改变其中的数据结构,即在NumPy数组中仍然使用字典格式进行存储。在采样时,如果传入大小是0,则返回整个缓冲区中的所有数据,以支持在同略学习算法的训练需求。
目前数据缓冲区的类型有:最基本的重放缓冲区(Replay Buffer)、优先级经验重放缓冲区(Prioritized Replay Buffer)支持优先权重采样、向量化重放缓冲区(Vector Replay Buffer)能够支持任意多的环境往里面添加数据而不破坏数据的时间顺序。此外数据缓冲区还支持历史数据堆叠采样(例如给定采样时间下标 和堆叠帧数 ,返回堆叠的观测值 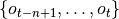 )和多模态数据存储(需要存储的数据可以是一个字典)。在将来还将会支持事后经验回放算法
[ACR+17] (Hindsight Experience Replay,HER)。
)和多模态数据存储(需要存储的数据可以是一个字典)。在将来还将会支持事后经验回放算法
[ACR+17] (Hindsight Experience Replay,HER)。
环境(Env)¶
环境接口遵循OpenAI Gym [BCP+16] 定义的通用接口,即每次调用 step 函数时,需要输入一个动作 ,返回一个四元组:下一个观测值 、这个时刻采取动作值 所获得的奖励 、环境结束标识符  、以及环境返回的其他信息 。
、以及环境返回的其他信息 。
为使所有强化学习算法支持并行环境采样,天授封装了几个不同的向量化环境类,可以单线程循环执行每个环境,也可以多线程同时执行。每次调用 step 函数的语义和之前定义一致,区别在于增加了一步将所有信息堆叠起来组成一个NumPy数组的操作,并以第0个维度来区分是哪个环境产生的数据。
策略(Policy)¶
策略是强化学习算法的核心。智能体除了需要做出决策,还需不断地学习来自我改进。通过 深度强化学习问题的抽象凝练与平台整体设计 中对策略的抽象描述,可以将其拆分为4个模块:
__init__:策略的初始化,比如初始化自定义的模型(Model)、创建目标网络(Target Network)等;forward:从给定的观测值 中计算出动作值 ,在 图 2.2 中对应Policy到Model的调用和Collector到Policy的调用;process_fn:在获取训练数据之前和数据缓冲区进行交互,在 图 2.2 中对应Policy到Buffer的调用;learn:使用一个数据组进行策略的更新训练,在图 图 2.2 中对应Trainer到Policy的调用。post_process_fn:使用一个Batch的数据进行Buffer的更新(比如更新PER);update:最主要的接口。这个update函数先是从buffer采样出一个batch,然后调用process_fn预处理,然后learn更新策略,然后 post_process_fn完成一次迭代:process_fn -> learn -> post_process_fn。
不同算法中策略的具体实现将在 平台支持的深度强化学习算法 中进行详细分析讲解。
模型(Model)¶
模型为策略的核心部分。为了支持任意神经网络结构的定义,天授并未像其他平台一样显式地定义若干基类(比如MLPPolicy、CNNPolicy等),而是规定了模型与策略进行交互的接口,从而让用户有更大的自由度编写代码和训练逻辑。
模型的接口定义如下:
采集器(Collector)¶
采集器定义了策略与环境交互的过程。采集器主要包含``collect``函数:让给定的策略和环境交互 n_step 步、或者 n_episode 轮,并将交互过程中产生的数据存储进数据缓冲区中;
采集器理论上还可以支持多智能体强化学习的交互过程,将不同的数据缓冲区和不同策略联系起来,即可进行交互与数据采样。
天授还实现了异步采集器 AsyncCollector,它支持异步的环境采样(比如环境很慢或者step时间差异很大)。不过AsyncCollector的collect的语义和上面Collector有所不同,由于异步的特性,它只能保证**至少** n_step 或者 n_episode 地收集数据。
训练器(Trainer)¶
训练器负责最上层训练逻辑的控制,例如训练多少次之后进行策略和环境的交互。现有的训练器包括同策略学习训练器(On-policy Trainer)、异策略学习训练器(Off-policy Trainer)和离线策略学习训练器(Offline Trainer)。
平台未显式地将训练器抽象成一个类,因为在其他现有平台中都将类似训练器的实现抽象封装成一个类,导致用户难以二次开发。因此以函数的方式实现训练器,并提供了示例代码便于研究者进行定制化训练策略的开发。
算法伪代码与对应解释¶
接下来将通过一段伪代码的讲解来阐释上述所有抽象模块的应用。
s = env.reset()
buf = Buffer(size=10000)
agent = DQN()
for i in range(int(1e6)):
a = agent.compute_action(s)
s_, r, d, _ = env.step(a)
buf.store(s, a, s_, r, d)
s = s_
if i % 1000 == 0:
bs, ba, bs_, br, bd = buf.get(size=64)
bret = calc_return(2, buf, br, bd, ...)
agent.update(bs, ba, bs_, br, bd, bret)
以上伪代码描述了一个定制化两步回报DQN算法的训练过程。 表 2.1 描述了伪代码的解释与上述各个模块的具体对应关系。
行 |
伪代码 |
解释 |
对应天授平台实现 |
|---|---|---|---|
1 |
s = env.reset() |
环境初始化 |
在Env中实现 |
2 |
buf = Buffer(size=10000) |
数据缓冲区初始化 |
buf = ReplayBuffer( size=10000) |
3 |
agent = DQN() |
策略初始化 |
policy.__init__(...) |
4 |
for i in range(int(1e6)): |
描述训练过程 |
在Trainer中实现 |
5 |
a = agent.compute_action(s) |
计算动作值 |
policy(batch, ...) |
6 |
s_, r, d, _ = env.step(a) |
与环境交互 |
collector.collect(...) |
7 |
buf.store(s, a, s_, r, d) |
将交互过程中产生的数据存储到数据缓冲区中 |
collector.collect(...) |
8 |
s = s_ |
更新观测值 |
collector.collect(...) |
9 |
if i % 1000 == 0: |
每一千步更新策略 |
在Trainer中实现 |
10 |
bs, ba, bs_, br, bd = buf.get(size=64) |
从数据缓冲区中采样出数据 |
collector.sample( size=64) |
11 |
bret = calc_return(2, buf, br, bd, ...) |
计算两步回报 |
policy.process_fn( batch, buffer, indice) |
12 |
agent.update(bs, ba, bs_, br, bd, bret) |
训练智能体 |
policy.learn(batch, ...) |
平台外围支持¶
命名由来¶
该强化学习平台被命名为“天授”。天授的字面含义是上天所授,引申含义为与生俱来的天赋。强化学习算法是不断与环境交互进行学习,在这个过程中没有人类的干预。取名“天授”是为了表明智能体没有向所谓的“老师”取经,而是通过与环境的不断交互自学成才。图 2.3 展示了天授平台的标志,左侧采用渐变颜色融合了青铜文明元素,是一个大写的字母“T”,右侧是天授拼音。
图 2.3:天授平台标志¶
文档教程¶
天授提供了一系列针对平台的文档和教程,使用ReadTheDocs 1 第三方平台进行自动部署与托管服务。目前部署在 https://tianshou.readthedocs.io/ 中,预览页面如 图 2.4 所示。
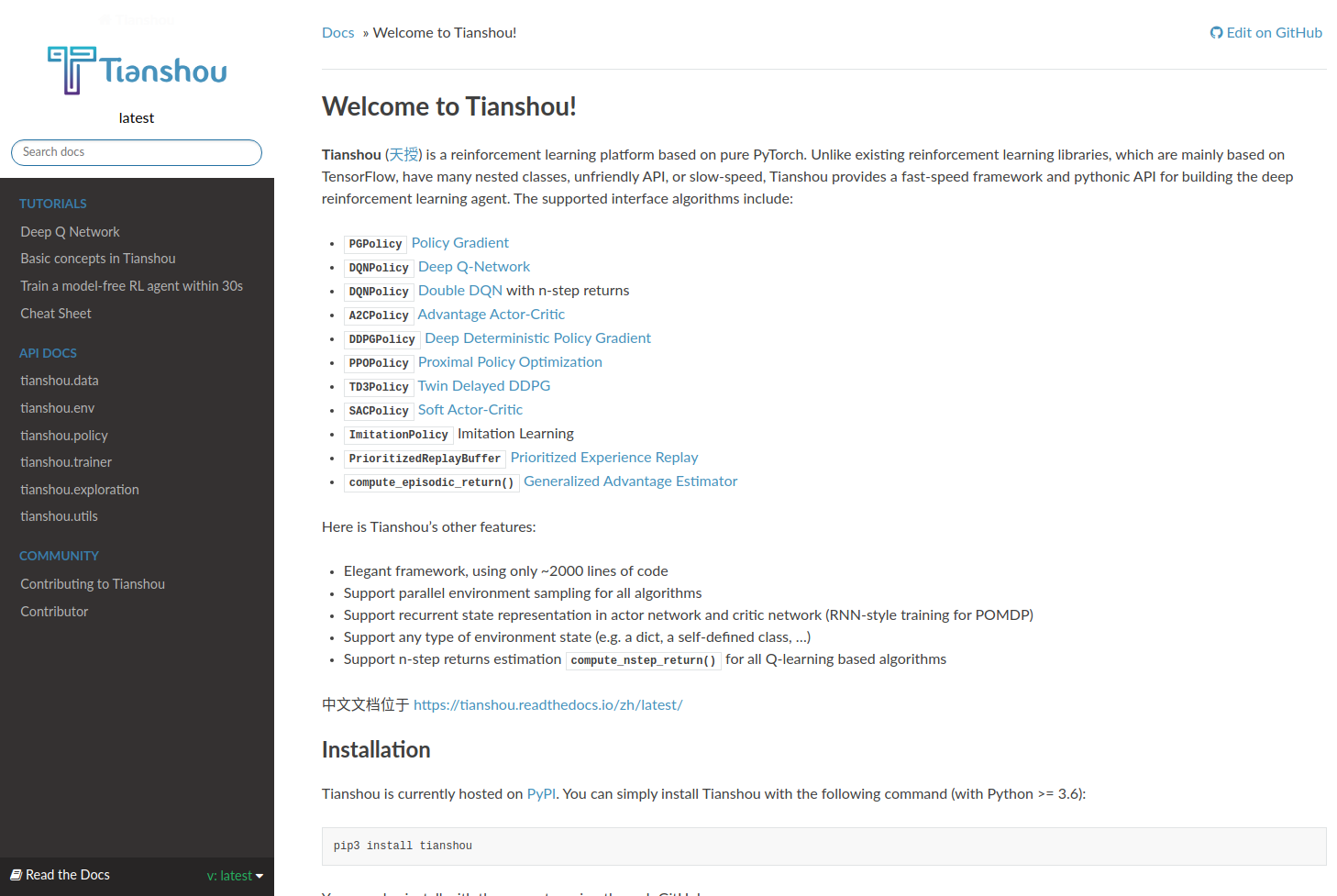
图 2.4:天授文档页面¶
单元测试¶
天授具有较为完善的单元测试,使用GitHub Actions 2 进行持续集成。在每次单元测试中,均包含代码风格测试、类型测试、功能测试、性能测试、文档测试五个部分,其中性能测试是对所有天授平台中实现的强化学习算法进行整个过程的完整训练和测试,一旦没有在规定的训练限制条件内达到能够解决对应问题的效果,则不予通过测试。
目前天授平台的单元测试代码覆盖率达到了94%,可以在第三方网站 https://codecov.io/gh/thu-ml/tianshou 中查看详细情况。图 2.5 展示了天授某次单元测试的具体结果。

图 2.5:天授单元测试结果¶
发布渠道¶
目前天授平台的发布渠道为PyPI 3 和 Conda 4。用户可以通过直接运行命令
$ pip install tianshou
或者
$ conda install tianshou -c conda-forge
进行平台的安装,十分方便。图 2.6 显示了天授在PyPI平台的发布界面。

图2.6:天授在PyPI平台的发布界面¶
小结¶
本章节介绍了深度强化学习的基本定义与问题描述,将各种不同的强化学习算法进行模块化抽象,并据此阐述了平台各个模块的实现,最后简单介绍了平台的其他特点。