Deep Q Network¶
深度强化学习在很多应用场景中表现惊艳,比如DQN [MKS+15] 就是一个很好的例子,在Atari游戏中一鸣惊人。在本教程中,我们会逐步展示如何在Cartpole任务上使用天授训练一个DQN智能体。 完整的代码位于 test/discrete/test_dqn.py。
与现有深度强化学习平台(比如 RLlib)不同,它们将超参数、网络结构等弄成一个config.yaml。天授从代码层面上提供了一个简洁的搭建方式。
创建环境¶
首先创建与智能体交互的环境。环境接口遵循 OpenAI Gym。运行如下命令:
import gym
import tianshou as ts
env = gym.make('CartPole-v0')
CartPole-v0是一个很简单的离散动作空间场景,DQN也是为了解决这种任务。在使用不同种类的强化学习算法前,您需要了解每个算法是否能够应用在离散动作空间场景 / 连续动作空间场景中,比如像DDPG [LHP+16] 就只能用在连续动作空间任务中,其他基于策略梯度的算法可以用在任意这两个场景中。
并行环境装饰器¶
此处定义训练环境和测试环境。使用原来的 gym.Env 当然是可以的:
train_envs = gym.make('CartPole-v0')
test_envs = gym.make('CartPole-v0')
天授提供了向量化环境装饰器,比如 VectorEnv、SubprocVectorEnv 和 RayVectorEnv。可以像下面这样使用:
train_envs = ts.env.DummyVectorEnv([lambda: gym.make('CartPole-v0') for _ in range(8)])
test_envs = ts.env.DummyVectorEnv([lambda: gym.make('CartPole-v0') for _ in range(100)])
此处在 train_envs 建立了8个环境,在 test_envs 建立了100个环境。接下来为了展示需要,使用后面那块代码。
建立网络¶
天授支持任意的用户定义的网络和优化器,但是需要遵循既定API,比如像下面这样:
import torch, numpy as np
from torch import nn
class Net(nn.Module):
def __init__(self, state_shape, action_shape):
super().__init__()
self.model = nn.Sequential(*[
nn.Linear(np.prod(state_shape), 128), nn.ReLU(inplace=True),
nn.Linear(128, 128), nn.ReLU(inplace=True),
nn.Linear(128, 128), nn.ReLU(inplace=True),
nn.Linear(128, np.prod(action_shape))
])
def forward(self, obs, state=None, info={}):
if not isinstance(obs, torch.Tensor):
obs = torch.tensor(obs, dtype=torch.float)
batch = obs.shape[0]
logits = self.model(obs.view(batch, -1))
return logits, state
state_shape = env.observation_space.shape or env.observation_space.n
action_shape = env.action_space.shape or env.action_space.n
net = Net(state_shape, action_shape)
optim = torch.optim.Adam(net.parameters(), lr=1e-3)
定义网络的规则如下:
输入
obs,观测值,为numpy.ndarray、torch.Tensor、或者自定义的类、或者字典state,隐藏状态表示,为RNN使用,可以为字典或者numpy.ndarray或者torch.Tensorinfo,环境信息,由环境提供,是一个字典
输出
logits:网络的原始输出,会被用来计算Policy,比如输出Q值,然后在DQNPolicy中后续会进一步计算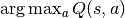 ;又比如PPO [SWD+17] 算法中,如果使用对角高斯策略,则
;又比如PPO [SWD+17] 算法中,如果使用对角高斯策略,则 logits为(mu, sigma)state:下一个隐藏状态,还是为了RNN
一些已经定义好并已经内置的MLP网络可以在 tianshou.utils.net.common、tianshou.utils.net.discrete 和 tianshou.utils.net.continuous 中找到。
初始化策略¶
我们使用上述代码中定义的 net 和 optim,以及其他超参数,来定义一个策略。此处定义了一个有目标网络(Target Network)的DQN策略:
policy = ts.policy.DQNPolicy(net, optim, discount_factor=0.9, estimation_step=3, target_update_freq=320)
定义采集器¶
采集器(Collector)是天授中的一个关键概念。它定义了策略与不同环境交互的逻辑。在每一回合(step)中,采集器会让策略与环境交互指定数目(至少)的步数或者轮数,并且会将产生的数据存储在重放缓冲区中。
train_collector = ts.data.Collector(policy, train_envs, ts.data.VectorReplayBuffer(20000, 10), exploration_noise=True)
test_collector = ts.data.Collector(policy, test_envs, exploration_noise=True)
使用训练器训练策略¶
天授提供了两种类型的训练器,onpolicy_trainer 和 offpolicy_trainer,分别对应同策略学习和异策略学习。
训练器会在 stop_fn 达到条件的时候停止训练。由于DQN是一种异策略算法,因此使用 offpolicy_trainer 进行训练:
result = ts.trainer.offpolicy_trainer(
policy, train_collector, test_collector,
max_epoch=10, step_per_epoch=10000, step_per_collect=10,
update_per_step=0.1, episode_per_test=100, batch_size=64,
train_fn=lambda epoch, env_step: policy.set_eps(0.1),
test_fn=lambda epoch, env_step: policy.set_eps(0.05),
stop_fn=lambda mean_rewards: mean_rewards >= env.spec.reward_threshold)
print(f'Finished training! Use {result["duration"]}')
每个参数的具体含义如下:
max_epoch:最大允许的训练轮数,有可能没训练完这么多轮就会停止(因为满足了stop_fn的条件)step_per_epoch:每个epoch要更新多少次策略网络step_per_collect:每次更新前要收集多少帧与环境的交互数据。上面的代码参数意思是,每收集10帧进行一次网络更新episode_per_test:每次测试的时候花几个rollout进行测试batch_size:每次策略计算的时候批量处理多少数据train_fn:在每个epoch训练之前被调用的函数,输入的是当前第几轮epoch和当前用于训练的env一共step了多少次。上面的代码意味着,在每次训练前将epsilon设置成0.1test_fn:在每个epoch测试之前被调用的函数,输入的是当前第几轮epoch和当前用于训练的env一共step了多少次。上面的代码意味着,在每次测试前将epsilon设置成0.05stop_fn:停止条件,输入是当前平均总奖励回报(the average undiscounted returns),返回是否要停止训练logger:天授支持 TensorBoard,可以像下面这样初始化:
from torch.utils.tensorboard import SummaryWriter
from tianshou.utils import BasicLogger
writer = SummaryWriter('log/dqn')
logger = BasicLogger(writer)
把logger送进去,训练器会自动把训练日志记录在里面。
训练器返回的结果是个字典,如下所示:
{
'train_step': 9246,
'train_episode': 504.0,
'train_time/collector': '0.65s',
'train_time/model': '1.97s',
'train_speed': '3518.79 step/s',
'test_step': 49112,
'test_episode': 400.0,
'test_time': '1.38s',
'test_speed': '35600.52 step/s',
'best_reward': 199.03,
'duration': '4.01s'
}
可以看出大概4秒就在CartPole任务上训练出来一个DQN智能体,在100轮测试中平均总奖励回报为199.03。
存储、导入策略¶
因为策略继承了 torch.nn.Module,所以存储和导入策略和PyTorch中的网络并无差别,如下所示:
torch.save(policy.state_dict(), 'dqn.pth')
policy.load_state_dict(torch.load('dqn.pth'))
可视化智能体的表现¶
采集器 Collector 支持渲染智能体的表现。下面的代码展示了以35FPS的帧率查看智能体表现:
policy.eval()
policy.set_eps(0.05)
collector = ts.data.Collector(policy, env, exploration_noise=True)
collector.collect(n_episode=1, render=1 / 35)
定制化训练器¶
天授为了能够支持用户的定制化训练器,在Trainer做了尽可能少的封装。使用者可以自由地编写自己所需要的训练策略,比如:
# 在正式训练前先收集5000帧数据
train_collector.collect(n_step=5000, random=True)
policy.set_eps(0.1)
for i in range(int(1e6)): # 训练总数
collect_result = train_collector.collect(n_step=10)
# 如果收集的episode平均总奖励回报超过了阈值,或者每隔1000步,
# 就会对policy进行测试
if collect_result['rews'].mean() >= env.spec.reward_threshold or i % 1000 == 0:
policy.set_eps(0.05)
result = test_collector.collect(n_episode=100)
if result['rews'].mean() >= env.spec.reward_threshold:
print(f'Finished training! Test mean returns: {result["rews"].mean()}')
break
else:
# 重新设置eps为0.1,表示训练策略
policy.set_eps(0.1)
# 使用采样出的数据组进行策略训练
losses = policy.update(64, train_collector.buffer)