平台使用实例¶
实例一:在CartPole-v0环境中运行DQN算法¶
本实例将使用天授平台从头搭建整个训练流程,并获得一个能在平均10秒之内解决CartPole-v0环境的的DQN [MKS+15] 智能体。
首先导入相关的包,并且定义相关参数:
import gym, torch, numpy as np, torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
import tianshou as ts
task = 'CartPole-v0'
lr = 1e-3
gamma = 0.9
n_step = 4
eps_train, eps_test = 0.1, 0.05
epoch = 10
step_per_epoch = 10000
step_per_collect = 10
target_freq = 320
batch_size = 64
train_num, test_num = 10, 100
buffer_size = 20000
writer = SummaryWriter('log/dqn')
创建向量化环境从而能够并行采样:
# 也可以用 SubprocVectorEnv
train_envs = ts.env.DummyVectorEnv([
lambda: gym.make(task) for _ in range(train_num)])
test_envs = ts.env.DummyVectorEnv([
lambda: gym.make(task) for _ in range(test_num)])
使用PyTorch原生定义的网络结构,并定义优化器:
class Net(nn.Module):
def __init__(self, state_shape, action_shape):
super().__init__()
self.model = nn.Sequential(*[
nn.Linear(np.prod(state_shape), 128),
nn.ReLU(inplace=True),
nn.Linear(128, 128), nn.ReLU(inplace=True),
nn.Linear(128, 128), nn.ReLU(inplace=True),
nn.Linear(128, np.prod(action_shape))
])
def forward(self, s, state=None, info={}):
if not isinstance(s, torch.Tensor):
s = torch.tensor(s, dtype=torch.float)
batch = s.shape[0]
logits = self.model(s.view(batch, -1))
return logits, state
env = gym.make(task)
state_shape = env.observation_space.shape or env.observation_space.n
action_shape = env.action_space.shape or env.action_space.n
net = Net(state_shape, action_shape)
optim = torch.optim.Adam(net.parameters(), lr=lr)
初始化策略(Policy)和采集器(Collector):
policy = ts.policy.DQNPolicy(
net, optim, gamma, n_step,
target_update_freq=target_freq)
train_collector = ts.data.Collector(
policy, train_envs, ts.data.VectorReplayBuffer(buffer_size, train_num),
exploration_noise=True)
test_collector = ts.data.Collector(policy, test_envs, exploration_noise=True)
开始训练:
result = ts.trainer.offpolicy_trainer(
policy, train_collector, test_collector, max_epoch=epoch,
step_per_epoch=step_per_epoch, step_per_collect=step_per_collect,
update_per_step=1 / step_per_collect, episode_per_test=test_num,
batch_size=batch_size, logger=ts.utils.BasicLogger(writer),
train_fn=lambda epoch, env_step: policy.set_eps(0.1),
test_fn=lambda epoch, env_step: policy.set_eps(0.05),
stop_fn=lambda mean_rewards: mean_rewards >= env.spec.reward_threshold)
print(f'Finished training! Use {result["duration"]}')
会有进度条显示,并且在大约10秒内训练完毕,结果如下:
Epoch #1: 95%|#8| 9480/10000 [00:04<00:00, ..., rew=200.00]
Finished training! Use 4.79s
可以将训练完毕的策略模型存储至文件中或者从已有文件中导入模型权重:
torch.save(policy.state_dict(), 'dqn.pth')
policy.load_state_dict(torch.load('dqn.pth'))
可以以每秒35帧的速率查看智能体与环境交互的结果:
policy.eval()
policy.set_eps(0.05)
collector = ts.data.Collector(policy, env, exploration_noise=True)
collector.collect(n_episode=1, render=1 / 35)
查看TensorBoard中存储的结果:
tensorboard --logdir log/dqn
结果如 图 5.1 所示。
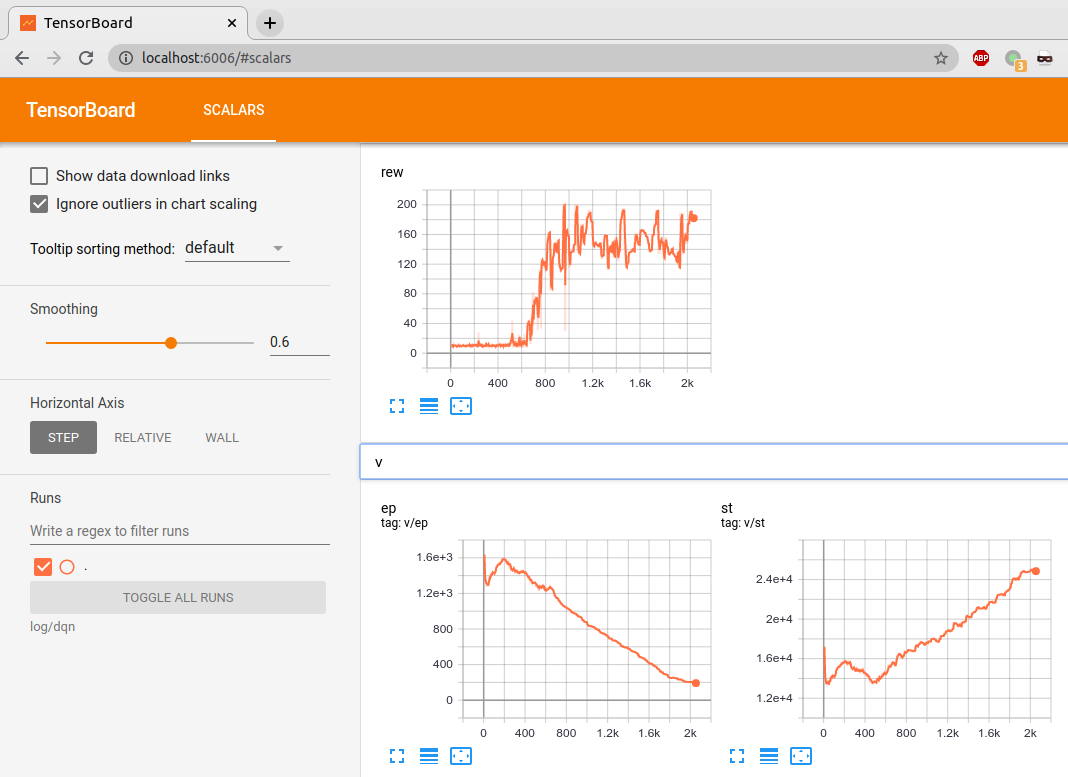
图 5.1:TensorBoard可视化训练过过程¶
当然,如果想要定制化训练策略而不使用训练器提供的现有逻辑,也是可以的。下面的代码展示了如何定制化训练策略:
# 在正式训练前先收集5000帧数据
train_collector.collect(n_step=5000, random=True)
policy.set_eps(0.1)
for i in range(int(1e6)): # 训练总数
collect_result = train_collector.collect(n_step=10)
# 如果收集的episode平均总奖励回报超过了阈值,或者每隔1000步,
# 就会对policy进行测试
if collect_result['rews'].mean() >= env.spec.reward_threshold or i % 1000 == 0:
policy.set_eps(0.05)
result = test_collector.collect(n_episode=100)
if result['rews'].mean() >= env.spec.reward_threshold:
print(f'Finished training! Test mean returns: {result["rews"].mean()}')
break
else:
# 重新设置eps为0.1,表示训练策略
policy.set_eps(0.1)
# 使用采样出的数据组进行策略训练
losses = policy.update(64, train_collector.buffer)
实例二:循环神经网络的训练¶
在POMDP场景中往往需要循环神经网络的训练支持。此处为简单起见,仍然以实例一中的场景和代码为基础进行展示。需要的改动如下:
首先修改模型为LSTM:
class Recurrent(nn.Module):
def __init__(self, state_shape, action_shape):
super().__init__()
self.fc1 = nn.Linear(np.prod(state_shape), 128)
self.nn = nn.LSTM(input_size=128, hidden_size=128,
num_layers=3, batch_first=True)
self.fc2 = nn.Linear(128, np.prod(action_shape))
def forward(self, s, state=None, info={}):
if not isinstance(s, torch.Tensor):
s = torch.tensor(s, dtype=torch.float)
# s [bsz, len, dim] (training)
# or [bsz, dim] (evaluation)
if len(s.shape) == 2:
bsz, dim = s.shape
length = 1
else:
bsz, length, dim = s.shape
s = self.fc1(s.view([bsz * length, dim]))
s = s.view(bsz, length, -1)
self.nn.flatten_parameters()
if state is None:
s, (h, c) = self.nn(s)
else:
# we store the stack data with [bsz, len, ...]
# but pytorch rnn needs [len, bsz, ...]
s, (h, c) = self.nn(s, (
state['h'].transpose(0, 1).contiguous(),
state['c'].transpose(0, 1).contiguous()))
s = self.fc2(s[:, -1])
# make sure the 0-dim is batch size: [bsz, len, ...]
return s, {'h': h.transpose(0, 1).detach(),
'c': c.transpose(0, 1).detach()}
其次重新定义策略,并将 train_collector
中的重放缓冲区设置成堆叠采样模式,堆叠帧数  为4:
为4:
env = gym.make(task)
state_shape = env.observation_space.shape or env.observation_space.n
action_shape = env.action_space.shape or env.action_space.n
net = Recurrent(state_shape, action_shape)
optim = torch.optim.Adam(net.parameters(), lr=lr)
policy = ts.policy.DQNPolicy(
net, optim, gamma, n_step,
target_update_freq=target_freq)
train_collector = ts.data.Collector(
policy, train_envs,
ts.data.VectorReplayBuffer(buffer_size, train_num, stack_num=4),
exploration_noise=True)
test_collector = ts.data.Collector(policy, test_envs, exploration_noise=True)
即可使用实例一中的代码进行正常训练,结果如下:
Epoch #2: 84%|#4| 8420/10000 [00:21<00:03, ..., rew=200.00]
Finished training! Use 37.22s
实例三:多模态任务训练¶
在像机器人抓取之类的任务中,智能体会获取多模态的观测值。天授完整保留了多模态观测值的数据结构,以数据组的形式给出,并且能方便地支持分片操作。以Gym环境中的“FetchReach-v1”为例,每次返回的观测值是一个字典,包含三个元素“observation”、“achieved_goal”和“desired_goal”。
在实例一代码的基础上进行修改:
task = 'FetchReach-v1'
train_envs = ts.env.DummyVectorEnv([
lambda: gym.make(task) for _ in range(train_num)])
test_envs = ts.env.DummyVectorEnv([
lambda: gym.make(task) for _ in range(test_num)])
class Net(nn.Module):
def __init__(self, state_shape, action_shape):
super().__init__()
self.model = nn.Sequential(*[
nn.Linear(np.prod(state_shape), 128),
nn.ReLU(inplace=True),
nn.Linear(128, 128), nn.ReLU(inplace=True),
nn.Linear(128, 128), nn.ReLU(inplace=True),
nn.Linear(128, np.prod(action_shape))
])
def forward(self, s, state=None, info={}):
o = s.observation
# s.achieved_goal, s.desired_goal are also available
if not isinstance(o, torch.Tensor):
o = torch.tensor(o, dtype=torch.float)
batch = o.shape[0]
logits = self.model(o.view(batch, -1))
return logits, state
env = gym.make(task)
env.spec.reward_threshold = 1e10
state_shape = env.observation_space.spaces['observation']
state_shape = state_shape.shape
action_shape = env.action_space.shape
net = Net(state_shape, action_shape)
optim = torch.optim.Adam(net.parameters(), lr=lr)
剩下的代码与实例一一致,可以直接运行。通过对比可以看出,只需改动神经网络中 forward 函数的  参数的处理即可。
参数的处理即可。