主要符号对照表¶
符号 |
说明 |
|---|---|
RL |
强化学习 (Reinforcement Learning) |
MFRL |
免模型强化学习 (Model-free Reinforcement Learning) |
MBRL |
基于模型的强化学习 (Model-based Reinforcement Learning) |
MARL |
多智能体强化学习 (Multi-agent Reinforcement Learning) |
MetaRL |
元强化学习 (Meta Reinforcement Learning) |
IL |
模仿学习 (Imitation Learning) |
On-policy |
同策略 |
Off-policy |
异策略 |
MDP |
马尔科夫决策过程 (Markov Decision Process) |
POMDP |
部分可观测马尔科夫决策过程 (Partially Observable Markov Decision Process) |
Agent |
智能体 |
|
策略 |
Actor |
动作(网络),又称作策略(网络) |
Critic |
评价(网络) |
|
状态 |
|
观测值,为状态的一部分, |
|
动作 |
|
奖励 |
|
结束符,0表示未结束,1表示结束 |
|
在一个轨迹中时刻 |
|
在当前状态 |
|
在当前状态 |
|
折扣因子,作为对未来回报不确定性的一个约束项, |
|
累计折扣回报, |
|
随机性策略,表示获取状态 |
|
确定性策略,表示获取状态 |
|
状态值函数(State-Value Function),表示状态 |
|
使用策略 |
|
动作值函数(Action-Value Function),表示状态 |
|
使用策略 |
|
优势函数, |
Batch |
数据组 |
Buffer |
数据缓冲区 |
Replay Buffer |
重放缓冲区 |
RNN |
循环神经网络(Recurrent Neural Network) |
 ,Policy
,Policy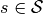 ,State
,State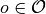 ,Observation
,Observation
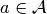 ,Action
,Action ,Reward
,Reward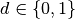 ,Done
,Done
 的状态、观测值、动作、奖励和结束符
的状态、观测值、动作、奖励和结束符
 采取动作
采取动作  之后,转移到状态
之后,转移到状态 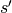 的概率;
的概率;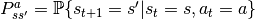
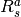
![R_s^a=\mathbb{E}[r_t|s_t=s, a_t=a]](../_images/math/3ffeb20700785452a755b3d3243e1ade233e7ad5.png)
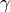
![\gamma\in [0, 1]](../_images/math/909ab24635bb60fd6a241e394fed502d75262735.png)
 ,Return
,Return



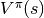
![V^\pi(s)=\mathbb{E}_{\pi} [G_t|s_t=s]](../_images/math/11b19b9ad4ac3af288feeafd626320c8fec2ba1e.png)

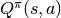
![Q^\pi(s, a) = \mathbb{E}_{a\sim \pi} [G_t|s_t=s, a_t=a]](../_images/math/417dce0626a7a26ce0d91a0dd2ddb69c550cac80.png)

